
Comparative Analysis of Face Detection Models: MTCNN, YOLO, and a Hybrid Approach
DOI:
https://doi.org/10.26438/ijsrcse.v13i3.668Keywords:
Face Detection, YOLO, MTCNN, Hybrid Model, Comparison, Algorithm OptimizationAbstract
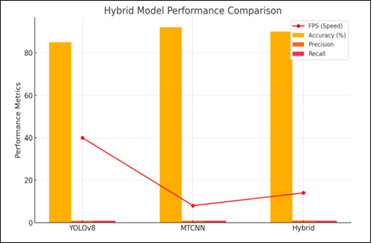
Face detection is a vital subroutine in many computer vision systems, such as facial recognition systems, emotion detection systems and surveillance systems. Two of the many such algorithms that have emerged powerful in terms of accuracy as well as computation efficiency are Multi-task Cascaded Convolutional Networks (MTCNN) and You Only Look Once (YOLO). This paper involves a comparative review of MTCNN, YOLO and a Hybrid Model that fuses the two methods. The models are trained on the fareselmenshawii/face-detection-dataset and the performance is measured by accuracy, running time and the stability of detecting the faces. The experimental findings show that there are apparent trade-offs that exist between speed and detection accuracy across the models, but the hybrid strategy shows a balanced execution, as it efficiently takes this advantage of the strengths of both MTCNN and YOLO.
References
K. Zhang, Z. Zhang, Z. Li and Y. Qiao, “Joint face detection and alignment using multitask cascaded convolutional networks,” IEEE signal processing letters, vol. 23, p. 1499–1503, 2016.
J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
B. Xu, W. Wang, L. Guo, G. Chen, Y. Wang, W. Zhang and Y. Li, “Evaluation of deep learning for automatic multi-view face detection in cattle,” Agriculture, vol. 11, p. 1062, 2021.
E. M. F. Caliwag, A. Caliwag, M. E. Morocho-Cayamcela and W. Lim, “Thermal Camera Face Detection and Alignment using MTCNN,” 한국통신학회 학술대회논문집, p. 319–321, 2020.
P. Viola and M. Jones, “Rapid object detection using a boosted cascade of simple features,” in Proceedings of the 2001 IEEE computer society conference on computer vision and pattern recognition. CVPR 2001, 2001.
H. A. Rowley, S. Baluja and T. Kanade, “Neural network-based face detection,” IEEE Transactions on pattern analysis and machine intelligence, vol. 20, p. 23–38, 1998.
T.-Y. Lin, P. Goyal, R. Girshick, K. He and P. Dollár, “Focal loss for dense object detection,” in
Proceedings of the IEEE international conference on computer vision, 2017.
Z. Lu, C. Zhou, X. Xuyang and W. Zhang, “Face detection and recognition method based on improved convolutional neural network,” International Journal of Circuits, Systems and Signal Processing, vol. 15, p. 774–781, 2021.
M. Tan and Q. Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,” in International conference on machine learning, 2019.
K. He, X. Zhang, S. Ren and J. Sun, “Deep residual learning for image recognition,” in
Proceedings of the IEEE conference on computer vision and pattern recognition, 2016.
N. C. Basjaruddin, E. Rakhman, Y. Sudarsa, M. B. Z. Asyikin and S. Permana, “Attendance system with face recognition, body temperature, and use of mask using multi-task cascaded convolutional neural network (MTCNN) Method,” Green Intelligent Systems and Applications, vol. 2, p. 71–83, 2022.
M. Ali, A. Diwan and D. Kumar, “Attendance system optimization through deep learning face recognition,” International Journal of Computing and Digital Systems, vol. 15, p. 1527–1540, 2024.
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani,
M. Minderer, G. Heigold, S. Gelly and others, “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Arun Sharma, Kunika, Riya, Mayank Chopra, Pradeep Chouksey, Parveen Sadotra

This work is licensed under a Creative Commons Attribution 4.0 International License.
Authors contributing to this journal agree to publish their articles under the Creative Commons Attribution 4.0 International License, allowing third parties to share their work (copy, distribute, transmit) and to adapt it, under the condition that the authors are given credit and that in the event of reuse or distribution, the terms of this license are made clear.



