
A Machine Learning Framework for Automated Data Cleaning and Anomaly Detection in Large Datasets
DOI:
https://doi.org/10.26438/ijsrcse.v13i3.679Keywords:
Automated Data Cleaning, Anomaly Detection, Data Imputation, Machine Learning, Dimensionality Reduction, Data QualityAbstract
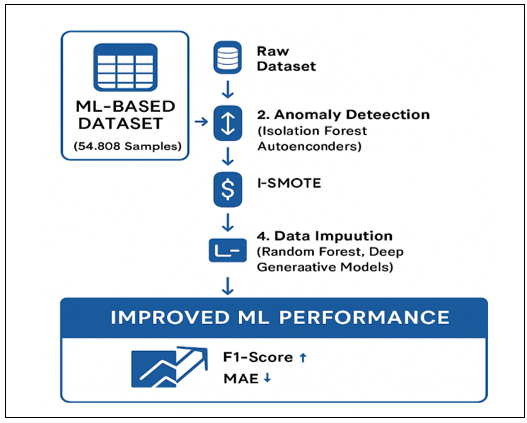
High-quality data is essential for robust machine learning applications, yet large datasets are often compromised by anomalies, missing values, and inconsistencies. This study proposes a novel machine learning framework for automated data cleaning and anomaly detection, integrating dimensionality reduction, anomaly detection, and data imputation techniques. The framework employs Isolation Forests and Autoencoders for anomaly detection, Principal Component Analysis (PCA) and t-SNE for dimensionality reduction, and Random Forest and deep generative models for imputing missing or erroneous data. Evaluated on diverse real-world datasets from finance, healthcare, and manufacturing, the framework achieves high precision (up to 0.88) and F1-scores (up to 0.84) in anomaly detection and low Mean Absolute Error (as low as 0.015) in imputation, significantly enhancing data quality and downstream model performance. The results underscore the framework’s applicability across domains, reducing manual preprocessing efforts. Future research will focus on extending the framework to real-time data streams and exploring domain-specific anomaly correction strategies.
References
R. Nasfi, G. de Tré, and A. Bronselaer, “Improving data cleaning by learning from unstructured textual data,” IEEE Access, Vol.13, Issue.1, pp.36470–36491, 2025.
V. Nguyen, N. Chung, G. Balaji, K. Rudzki, and A. Hoang, “Internet of things-driven approach integrated with explainable machine learning models for ship fuel consumption prediction,” Alexandria Engineering Journal, Vol.118, Issue.1, pp.664–680, 2025.
C. Li, C. Liu, W. Ju, Y. Zhong, and Y. Li, “Prediction of teaching quality in the context of smart education,” Discover Artificial Intelligence, Vol.5, Issue.1, pp.1–15, 2025.
P.-O. Côté, A. Nikanjam, N. Ahmed, et al., “Data cleaning and machine learning: A systematic literature review,” Automated Software Engineering, Vol.31, Issue.54, pp.1–22, 2024.
S. Choi and S. Yoon, “GPT-based data-driven urban building energy modeling (GPT-UBEM),” Energy and Buildings, Vol.325, Issue.1, pp.1–10, 2024.
M. H. Ahmadilivani, M. Taheri, J. Raik, M. Daneshtalab, and M. Jenihhin, “A systematic literature review on hardware reliability assessment methods for deep neural networks,” ACM Computing Surveys, Vol.56, Issue.6, pp.1–39, 2024.
X. Miao, Y. Wu, L. Chen, Y. Gao, and J. Yin, “An experimental survey of missing data imputation algorithms,” IEEE Transactions on Knowledge and Data Engineering, Vol.35, Issue.7, pp.6630–6650, 2023.
V. K. Tiwari, M. K. Bagwani, A. Gangwar, and K. Vishwakarma, “Real-time Signature-based Detection and Prevention of DDoS Attacks in Cloud Environments,” International Journal of Science and Research Archive, Vol.12, Issue.2, pp.2929–2935, 2024.
V. K. Tiwari, M. K. Bagwani, and A. Jain, “Implementing GrapesJS in Educational Platforms for Web Development Training on AWS,” International Journal of Scientific Research in Multidisciplinary Studies, Vol.10, Issue.8, pp.1–8, 2024.
V. K. Tiwari, A. Jain, R. Singh, and P. Singh, “Enhancing Outlier Detection and Dimensionality Reduction in Machine Learning for Extreme Value,” International Journal of Advanced Networking and Applications, Vol.15, Issue.6, pp.6204–6210, 2024.
V. N. Gudivada, D. Rao, and V. V. Raghavan, “Data quality considerations for big data and machine learning: Going beyond data cleaning and transformations,” IEEE Transactions on Knowledge and Data Engineering, Vol.32, Issue.7, pp.1311–1324, 2020.
Y. Li, J. Li, Y. Suhara, A. Doan, and W.-C. Tan, “Deep entity matching with pre-trained language models,” Proceedings of the VLDB Endowment, Vol.14, Issue.1, pp.50–60, 2020.
L. Sun and Y. Zhao, “Forecasting follies: Machine learning from human errors,” Journal of Risk and Financial Management, Vol.18, Issue.2, pp.60, 2025.
K. Pandey, “The Intelligent Workplace: AI and Automation Shaping the Future of Digital Workplaces,” International Journal of Scientific Research in Computer Science and Engineering (IJSRCSE), Vol.13, Issue.1, pp.1–10, 2024.
S. Adamu, A. A. Deba, and F. U. Zambuk, “Data Selection, Training, and Validation for Deployment of the Artificial Neural Networks to Predict Science Education Students’ Early Completion of University,” International Journal of Scientific Research in Computer Science and Engineering (IJSRCSE), Vol.13, Issue.1, pp.11–20, 2024.
M. Choubisa and B. Jajal, “Analysis of Secure Authentication for IoT using Token-based Access Control,” International Journal of Scientific Research in Computer Science and Engineering (IJSRCSE), Vol.13, Issue.1, pp.21–25, 2024.
M. Comuzzi, S. Kim, J. Ko, M. Salamov, C. Cappiello, and B. Pernici, “On the impact of low-quality activity labels in predictive process monitoring,” In the Proceedings of the 2025 Process Mining Workshops, India, pp.201–213, 2025.
A. Heidari, J. McGrath, I. F. Ilyas, and T. Rekatsinas, “HoloDetect: Few-shot learning for error detection,” In the Proceedings of the 2023 ACM SIGMOD International Conference on Management of Data, India, pp.829–846, 2023.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Jitendra Agrawal, Virendra Kumar Tiwari Thakur, Sanjay Thakur

This work is licensed under a Creative Commons Attribution 4.0 International License.
Authors contributing to this journal agree to publish their articles under the Creative Commons Attribution 4.0 International License, allowing third parties to share their work (copy, distribute, transmit) and to adapt it, under the condition that the authors are given credit and that in the event of reuse or distribution, the terms of this license are made clear.



